Einfaches Monitoring des Stromverbrauchs über Grafana
Update Oktober 2022
Im Artikel wird von der Nutzung einer InfluxDB in Version 1.* ausgegangen. Vor kurzem habe ich das Setup auf Version 2.* aktualisiert. Hier die aktualisierten Dateien welche im Artikel noch in alter Version referenziert werden:
- docker-compose.yml (nur InfluxDB ohne Grafana)
- Grafana Dashboard mit neuen Queries (Flux statt InfluxQL)
- Skript zur Datenabfrage und Verarbeitung
Da ich einen etwas genaueren Einblick in die Stromnutzung meiner Geräte haben wollte, habe ich mir ein Monitoring mittels Grafana und InfluxDB eingerichtet, in welchem ich eine detaillierte Auswertung über die genutzte Energie erhalte.
Die primären Komponenten sind hierbei ein TP-Link HS110 Smart Plug, ein Raspberry Pi und optional noch ein vServer oder ähnliches, welcher Grafana und InfluxDB als Anwendung bereitstellt und über das Internet verfügbar macht. Sollten die Anwendungen nur lokal im eigenen Netz erreichbar sein, wird ein solcher Server nicht benötigt.
Die Steckdose konnte ich im nahegelegenen Elektromarkt für 23€ erworben und sowohl den Pi, als auch den Server hatte ich ohnehin schon für andere Zwecke im Einsatz. Alles in allem war das ganze also kein teures Projekt.
Um den Aufbau etwas genauer darzustellen habe ich hier einmal die eben erwähnten Varianten dargestellt:
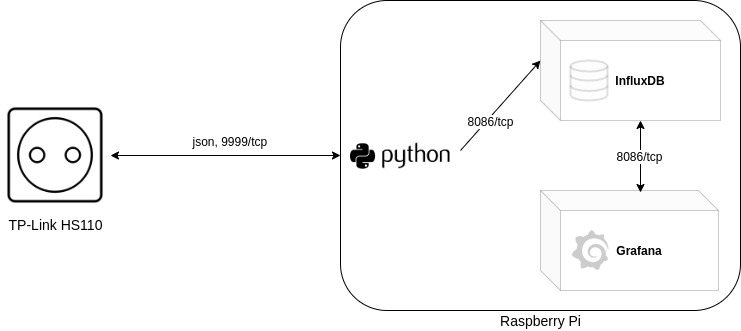
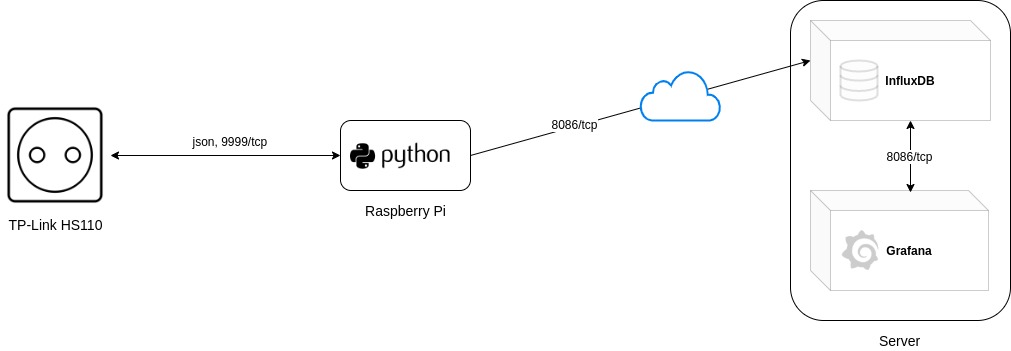
Einrichtung
Steckdose
Alles begann damit, dass ich die Steckdose einsteckte und mittels der App „Kasa“ einrichtete. Diese ist für Android und iOS verfügbar. Während der Einrichtung wird die Steckdose mit dem WLAN verbunden, woraufhin sie wie gewohnt eine IP Adresse bekommt und anschließend im Netzwerk erreichbar ist.
InfluxDB und Grafana
Anschließend richtete ich die Anwendungen InfluxDB und Grafana ein. InfluxDB dient als Datenbank zur Sicherung der Daten und mit Grafana lassen sich die Daten aus der Datenbank in einer schönen Art und Weise darstellen. In meinem Fall nutzte ich Docker-Compose um die Anwendungen zu betreiben. (hier ein Beispiel, wie mein Compose file ungefähr aussah: docker-compose.yml)
Die Anwendungen können aber auch auf anderem Wege installiert werden. Allerdings sollte beachtet werden, dass ich mit meinem Docker-Compose File direkt eine Datenbank initialisiere und einen Benutzer mit den entsprechenden Berechtigungen anlege. Werden die Anwendungen manuell installiert, muss dementsprechend auch manuell eine Datenbank und ein entsprechender Nutzer angelegt werden.
Datenverarbeitung durch Raspberry Pi
Als nächstes kam der Raspberry Pi zum Einsatz, welcher nun die Daten der Steckdose abfragen und in die Datenbank schreiben sollte. Um das zu erreichen orientierte ich mich an dem Artikel, welchen ich am Ende dieses Artikels verlinkt habe. In diesem wurde ein Python Skript genutzt, welches Anfragen an die Steckdose stellt und die Antwort der Steckdose in die Datenbank schreibt. Da das Skript so ausgelegt war, dass es in eine Graphite Datenbank schreibt, musste ich es für mich etwas anpassen. Außerdem hatte TP-Link seit Erstellung des Skriptes ein paar Änderungen bei der Abfrage der Daten eingebaut (wie hier am Ende des Artikels beschrieben), weshalb ich das Skript dahingehend ebenfalls anpassen musste.
Des Weiteren verweise ich im folgenden Skript noch darauf, dass das folgende Paket mittels „pip“ installiert werden muss, damit das Skript ausgeführt werden kann.
pip3 install influxdb
Nachdem ich meine Änderungen eingepflegt hatte sah das ganze dann wie folgt aus:
Mit den Variablen am Anfang des Skriptes werden die Verbindungsdetails zur InfluxDB definiert. Weiter unten in der Funktion „store_metrics“ habe ich dann definiert, wie die Daten in die Datenbank geschrieben werden sollen. Hierbei werden zwei measurements angelegt. „PowerData“ und „PowerUsage“. Measurements sind in etwa zu vergleichen mit Tabellen bei konventionellen Datenbanken. In „PowerData“ werden Werte wie die Spannung, Leistung und Stromstärke gespeichert. Da die HS110 Steckdose auch direkt Auskunft über den Gesamtverbrauch gibt, wird dieser zusätzlich noch in „PowerUsage“ gespeichert.
Wenn sowohl die Datenbank, als auch die Steckdose verfügbar sind, kann das Skript testweise ausgeführt werden. Wenn die Rückmeldung wie folgt aussieht, sollte das schreiben in die Datenbank erfolgreich gewesen sein.

Um das Skript nicht immer manuell laufen zu lassen, richtete ich einen systemd service ein, welcher dafür sorgt, dass das Skript im Hintergrund ausgeführt wird. Anschließend aktivierte ich den service, damit dieser bei jedem Systemstart automatisch ausgeführt wird.
nano /lib/systemd/system/hs110.service
[Unit] Description=HS110 Service After=syslog.target [Service] Type=simple User=root WorkingDirectory=/root/scripts/ ExecStart=/usr/bin/python3 /root/scripts/hs110-data-collect-influxdb.py StandardOutput=syslog StandardError=syslog [Install] WantedBy=multi-user.target
sudo systemctl enable hs110.service && sudo systemctl start hs110.service
Mit den bis zu diesem Punkt durchgeführten Schritten erreichte ich, dass die Stromdaten, welche von der Smarten Steckdose abgefragt werden, in eine Datenbank geschrieben werden. Im nächsten Schritt nutzte ich Grafana, um diese Daten abzufragen und darzustellen.
Darstellung
Zur Abfrage der Daten musste ich zunächst eine Verbindung zur Datenbank in Grafana eintragen. Im Bereich „Data Sources“ gab es bereits die Option eine InfluxDB hinzuzufügen. Nachdem ich die Zugangsdaten zu meiner InfluxDB eingetragen hatte und mir der Button „Save & Test“ eine positive Rückmeldung gab, konnte ich damit beginnen mein Dashboard zu erstellen. Die Verbindung zur Datenbank war somit erfolgreich.
Mit den Daten, welche ich aus der Datenbank lesen konnte, konnte ich mir diverse Anzeigen und Graphen anlegen. Bei einigen musste ich das Ergebnis vorher umrechnen, was aber kein großes Problem darstellte.
Da es den Artikel etwas sprengen würde, wenn ich jede einzelne Option in meinem Dashboard erklären würde, habe ich hier mal einen Export meines Dashboards im JSON Format erstellt, welchen jeder bei sich im Grafana einpflegen kann. Es sei zu beachten, dass in der JSON Datei von einer Data Source Namens „Steckdose“ ausgegangen wird und dass die Measurements „PowerData“ und „PowerUsage“ abgefragt werden. Diese Angaben müssen ggf. angepasst werden.
Link zur JSON Datei: https://gist.github.com/bjarneeins/076b874ef1027892d3b0bfa1df633fc5
Hier noch ein Screenshot des Dashboards, welches damit erstellt wird:
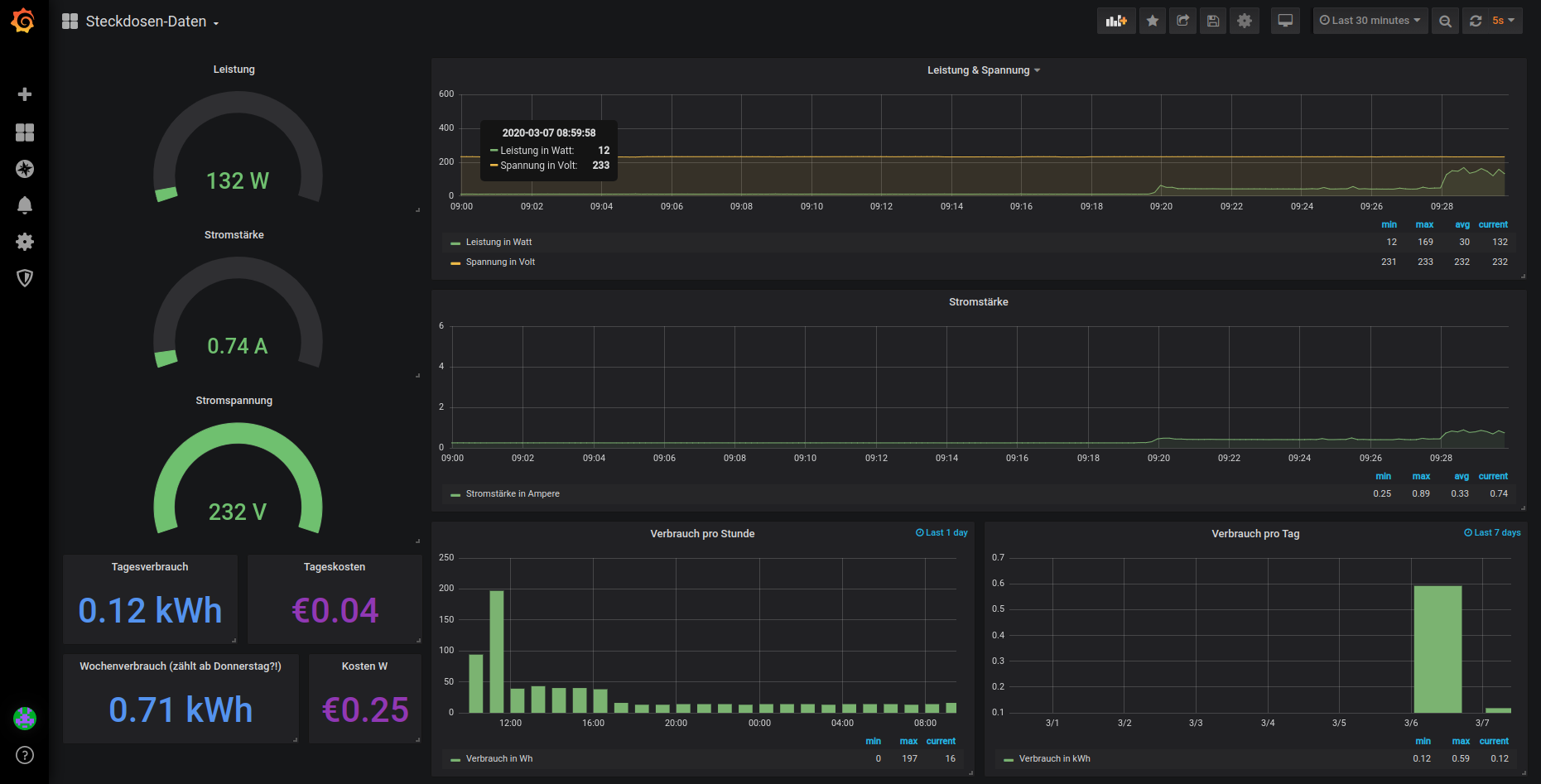
Mit dem Dashboard bekomme ich Auskunft über:
- die aktuelle Leistung in Watt, welche genutzt wird
- die Stromstärke in Ampere
- die anliegende Spannung in Volt
- den Stromverbrauch in Wh, unterteilt in Stunden
- den Stromverbrauch in kWh, unterteilt in Tage
- die Stromkosten pro Tag
- die Stromkosten pro Woche
Bei der Berechnung der Stromkosten gehe ich von einem Preis von 0,35€/kWh aus. Dieser kann natürlich auch höher oder niedriger sein.
Zusatz
Damit die Datenbank nicht stetig wächst, habe ich noch eine „Retention Policy“ eingerichtet, welche die Daten in 24h Paketen nach 4 Wochen löscht. Dazu habe ich die folgenden beiden Kommandos ausgeführt:
influx -username 'admin' -password 'geheim' -execute 'CREATE RETENTION POLICY "four_weeks" ON "dosedata" DURATION 4w REPLICATION 1'
influx -username 'admin' -password 'geheim' -execute 'ALTER RETENTION POLICY "four_weeks" ON "dosedata" SHARD DURATION 1d DEFAULT'
Abschluss
Aktuell ist das Setup nur so ausgelegt, dass die Daten von nur einer Steckdose genutzt werden (was für meinen Anwendungszweck auch vollkommen ausreicht). Der Aufwand um das ganze so einzurichten, dass Daten von mehreren Steckdosen eingelesen werden, sollte aber überschaubar sein.
Ich bin außerdem jederzeit offen für Verbesserungsvorschläge zum. Sei es zum Artikel allgemein oder nur zu einzelnen Skripten. Falls euch etwas auffällt, könnt ihr dies gerne in die Kommentare posten. 🙂
Außerdem werde ich darauf achten, sowohl den Artikel, als auch die Skripte zu ergänzen, wenn ich Änderungen an meinem Setup vornehmen sollte.
Inspiration zu dem Projekt holte ich mir von folgendem Artikel: https://www.beardmonkey.eu/tplink/hs110/2017/11/21/collect-and-store-realtime-data-from-the-tp-link-hs110.html
Außerdem entnam ich Informationen zum abfragen der Verbrauchsdaten der Steckdose aus folgendem Github Repository: https://github.com/softScheck/tplink-smartplug

CUPS Printserver für alte Drucker einrichten
VMware Workstation Pro kann unter Windows nicht ausgeführt werden (Fehlerbehebung)
TOP Artikel, bin beeindruckt.
Spannend! Ich werde das auf jeden Fall auch mal probieren!
Danke für die Anleitung. Habe es gleich ausprobiert. Läuft gut. Nur bei SSL (HTTPS) gab es immer Fehlermeldungen.
Habe bei mir auch alles ohne Probleme über SSL eingerichtet. Weisst du noch um was für Fehlermeldungen es sich handelte?
Hi , bekomme das nicht zum laufen 🙁
wenn ich das script *.py starte bekomme ich eine Fehlermeldung in Zeile 15
Traceback (most recent call last):
File „hs110-data-collect-influxdb.py“, line 15, in
from Influxdb import InfluxDBClient
Hey, das ist schade.
Hast du denn das entsprechende Paket installiert, auf welches im Kommentar (Zeile 14) hingewiesen wurde? (needs to be installed (pip3 install influxdb)) 🙂
Hey 🙂
erst mal Merci für die flotte Antwort … TOP
Ich muss gestehen das ich mit Docker usw. noch nicht gearbeitet habe und ich mir erst einlesen muss.
Also Docker und Docker Compose läuft
So und dann gehts schon los, Du hast ja das Docker -Compose File konfiguriert bzw auch die *.py Datei.
Welche Reihenfolge der Einrichtung muss ich den vornehmen?
Ein kleines TUT mit den erforderlichen Kommandos für den Raspi wären Mega.
Denn dann könnte ich auch die logik dahinter verstehen …
und „pip3 install influxdb“ hatte ich installiert aber erst nachdem ich das Composefile gestartet hatte. Ob das so stimmt weis ich leider nicht. bei ausführen des Compose files mecker die Kiste auch immer das er in bestimmte Ordner nicht schreiben kann (Rechteproblem) Boa viel oder 🙂
Ich finde aber deinen Ansatz Supi den genau das suche ich schon ne Weile
LG Erich
Hi,
entschuldige die etwas verspätete Antwort. Eventuell hast du es ja mittlerweile schon selbst gelöst.
Eine spezielle Reihenfolge gibt es für die Einrichtung nicht. Mit dem Docker-Compose File gebe ich an, wie die Anwendungen (Grafana, InfluxDB) laufen sollen. Zu Docker und Docker-Compose findest du im Netz reichlich Literatur. 🙂
Sobald die Anwendungen laufen, kannst du dich mit dem Python Skript beschäftigen. In diesem gibst du ziemlich am Anfang die Verbindungsinformationen zur Datenbank (Hostname, Port, Name der DB, PW, usw.) und die IP der Steckdose an. Anschließend kannst du das Skript einmal manuell ausführen. Wenn das klappt, können die Daten erfolgreich von der Steckdose abgefragt und in die Datenbank geschrieben werden. Danach habe ich das Skript einfach nur noch im Hintergrund ausführen lassen und die Daten mit Grafana aus der Datenbank gelesen.
Solltest du noch Fragen haben, kannst du dich auch gern direkt per Mail bei mir melden. Da bekommst du meist auch eine schnellere Antwort. 🙂
Beste Grüße
Hej,
was hast du bei Grafana eingestellt, um folgende Felder zu erstellen?
den Stromverbrauch in Wh, unterteilt in Stunden
den Stromverbrauch in kWh, unterteilt in Tage
die Stromkosten pro Tag
die Stromkosten pro Woche
Danke!
Hi,
für genau diesen Zweck hatte ich die .json Datei von meinem Grafana Dashboard exportiert und im Artikel verlinkt. Wenn du genau das gleiche Dashboard wie ich haben möchtest, könntest du dir diese in Grafana importieren.
Wenn du dir von Grund auf ein eigenes Dashboard bauen möchtest, sollten dir die folgenden Screenshots helfen. Da siehst du die von mir gesetzten Einstellungen. 🙂
Stromverbrauch in Wh (pro Stunde):
https://oprtr.org/wp-content/uploads/2020/12/usagehour.png
Stromverbrauch in kWh (pro Tag):
https://oprtr.org/wp-content/uploads/2020/12/usageday.png
Stromkosten pro Tag:
https://oprtr.org/wp-content/uploads/2020/12/costsday.png
Stromkosten pro Woche:
https://oprtr.org/wp-content/uploads/2020/12/costsweek.png
Hallo,
Ich habe auf einem RPi schon Grafana und InfluxDB installiert, InfluxDB habe ich dabei wie folgt installiert:
wget https://dl.influxdata.com/influxdb/releases/influxdb_1.8.3_amd64.deb
sudo dpkg -i influxdb_1.8.3_amd64.deb
Kann ich das Python Skript trotzdem verwenden oder geht das nicht, weil ich InfluxDB nicht über pip installiert habe?
Hi,
die manuelle Installation von InfluxDB (ohne Docker, wie bei mir) sollte ohne Probleme funktionieren. 🙂
Das influx Modul, welches ich in dem Tutorial mit pip installiert habe wird dennoch benötigt, um das Skript auszuführen. Du benötigst also InfluxDB als Anwendung (was du bereits installiert hast) und die Python Erweiterung „influxdb“, damit das Skript in der Lage ist eine Datenbankverbindung herzustellen.
Grüße
Achso, das habe ich falsch verstanden.
Dann vielen Dank für die schnelle Antwort und das tolle Skript!
gern 🙂
Hey Bjarne,
ich hab das mit der Retention Policy leider nicht ganz verstanden. Sind damit meine erfassten Daten nach 4 Woche futsch? Ich würde gerne die Auswertung über mindestens 1 Jahr so fein wie möglich laufen lassen. Ohne die Policy funktioniert der Verbrauch pro Tag und die Kosten ja leider nicht. Die beziehen sich ja auf die four_weeks .
Mein Ziel ist eine Auswertung auf Tag, Monat und Jahr machen zu können. 🙂
Danke schon mal für den super Artikel!
Gruß Jochen
Hi Jochen, ja da hast du Recht. Die Daten wären nach 4 wochen futsch. Bei mir ist das ja so gewollt.
Ohne die Retention Policy, so wie ich sie eingerichtet habe, funktionieren die von mir eingerichteten Verbrauchsmessungen für Tag bzw. Woche nicht. Da hast du auch Recht.
Du könntest die Retention Policy allerdings etwas umschreiben und die Duration hochsetzen (Hier mal ein Beispiel, welches für ein Jahr passen sollte):
influx -username 'admin' -password 'geheim' -execute 'CREATE RETENTION POLICY "one_year" ON "dosedata" DURATION 52w REPLICATION 1'Mit dem zweiten Befehl wird ja die Größe der Blöcke festgelegt, in welchen die Daten gespeichert werden sollen. Ich hatte in meinem Beispiel aller 24 Stunden eingerichtet. Somit wird jeder Block bzw. Tag, welcher älter als 4 Wochen ist, gelöscht.
Was in deinem Fall eventuell sinnvoller wäre (kannst du natürlich entscheiden):
influx -username 'admin' -password 'geheim' -execute 'ALTER RETENTION POLICY "one_year" ON "dosedata" SHARD DURATION 4w DEFAULT'Mit den beiden Befehlen sollten deine Daten also ein Jahr aufgehoben werden und jeder Monat (4 Wochen) sollte gelöscht werden, sobald er älter als 1 Jahr (52 Wochen) ist.
Bei der Abfrage in Grafana müsstest du dich dann entsprechend auf die Tabelle „one_year“ und nicht wie bei mir „four_weeks“ beziehen. 🙂
Beste Grüße,
Bjarne
Hallo Bjarne;
ich würde so gerne auch den Stromverbrauch so wie von Dir dargestellt in Grafana anzeigen. Ich habe dazu Dein Jason kopiert und gehofft, einfach anstelle deiner „Steckdose“ meinen Datenpunkt auszuwählen. Leider funktioniert das so nicht. Ich bin leider kein Held in Grafana und auch keiner in Jason.
Die Werte werden in einem normalen Grafen richtig angezeigt und sind also da… Mich interessiert nur die Darstellung Tagesverbrauch in Stunden und je Woche / Monat… Hast Du einen Tipp für mich?
Lieben Dank
Hi,
es gibt keine Stromspannung. Es gibt nur Strom oder Spannung aber nicht beides.
Da hab ich mich wohl als Laie geoutet. 😉 Habe es mal in der Grafana json und bei mir selbst angepasst.
Hier ne neue Version mit Unit-Descriptions.
https://gist.github.com/xpcone/58d76446fc13839fe98c581dbb092490
Hi, schöne das Skript. Leider klappt es bei mir nicht und ich kenne mich mit Python leider nicht gut aus.
Ich erhalte folgenden Fehler
root@statistik:~/scripts# python3 hs110-data-collect-influxdb2.py Traceback (most recent call last): File "/root/scripts/hs110-data-collect-influxdb2.py", line 117, in <module> run() File "/root/scripts/hs110-data-collect-influxdb2.py", line 112, in run store_metrics(emeter["current_ma"], emeter["voltage_mv"], emeter["power_mw"], emeter["total_wh"]) KeyError: 'current_ma' Exception in thread Thread-1: Traceback (most recent call last): File "/usr/lib/python3.9/threading.py", line 954, in _bootstrap_inner self.run() File "/usr/lib/python3.9/threading.py", line 1266, in run self.function(*self.args, **self.kwargs) File "/root/scripts/hs110-data-collect-influxdb2.py", line 112, in run store_metrics(emeter["current_ma"], emeter["voltage_mv"], emeter["power_mw"], emeter["total_wh"]) KeyError: 'current_ma' Exception in thread Thread-2: Traceback (most recent call last): File "/usr/lib/python3.9/threading.py", line 954, in _bootstrap_inner self.run() File "/usr/lib/python3.9/threading.py", line 1266, in run self.function(*self.args, **self.kwargs) File "/root/scripts/hs110-data-collect-influxdb2.py", line 112, in run store_metrics(emeter["current_ma"], emeter["voltage_mv"], emeter["power_mw"], emeter["total_wh"]) KeyError: 'current_ma' ...eine Idee, was ich vergessen haben könnte?
Hi, entschuldige die leicht verspätete Antwort. Die Fehlermeldung ist leider nicht sehr aussagekräftig, daher habe ich auch keine Idee was fehlen könnte.
Eventuell hast du es ja mittlerweile auch schon zum Laufen bekommen? 🙂